The fundamental problem that Twitter has is engagement. If engagement can be corrected, the whole Twitter ecosystem (and their stock price) will improve.
Improving Twitter engagement comes down to fixing the core consumption experience.
First of all what’s wrong with the consumption experience? In a nutshell, two problems:
- The signal-to-noise ratio of Twitter has declined dramatically as the service reached social saturation. There are simply too many messages from too many people in the stream — I call this “The Tragedy of the Comments” (yes, that was a pun). The issue is that since there is no economic disincentive to spam Twitter, nor any incentive for anyone to police or manage the common message space, it’s filling up with irrelevant / junk content and the amount of such content is growing rapidly. For users, it becomes very difficult to filter signal from all that noise. Users simply give up when faced with that level of overload. Why spend a lot of effort searching for needles in the haystack, when there are other ways (other apps, sites, etc.) to get a higher ratio of needles?
- The participation-to-reward ratio of Twitter has also declined dramatically with saturation. Because of the poor signal-to-noise ratio, the likelihood that anyone will see or respond to a Tweet you post, if you are not a major celebrity or media outlet, has declined far below the threshold of incentive. Why bother to Tweet when there is only a negligible chance anyone will see it or respond? The reward for participation has fallen too low for the majority of the user base to spend the effort.
There are several relatively easy steps Twitter can take to solve both of these problems, with better metadata and analytics in their apps. Making these changes would increase the usability of Twitter for most users and could radically improve Twitter’s metrics.
The Next-Generation Twitter App
I’m going to start this article with a concept for a next-gen Twitter app that makes it easier for consumers to track their interests in Twitter than ever before.
This app is designed around some additional metadata and filtering capabilities that I propose Twitter should set as priorities.
Here’s the basic concept of the app, and then there’s an illustration below.
This app should make it super easy to find or create new subscriptions for interests.
If you only want holiday recipes from top financial analysts, or video news about sports posted by major sports outlets, you can easily define these interests and start getting highly filtered relevant content about them, with a way to sort it by “signal” versus “noise.”
Users could be enabled to create and share their own interest subscription definitions, just like they share Twitter lists. Twitter could then provide a directory of public subscriptions, ranked by number of subscribers to each one, and this thing would take off.
A useful design pattern for this app comes from the world of RSS readers, where there was a lot of work done to come up with effective interfaces for keeping up with many different feeds of news and content. A simple 3-pane browser design pattern works best.
And of course the app could have other tabs for featured content theaters from Twitter and big paying sponsors — for example tabs could appear for any subscription interest that Twitter or a sponsor wants to promote. Users could then subscribe to the ones they want and they would be added to their interests on the left.
Here’s a simple schematic:
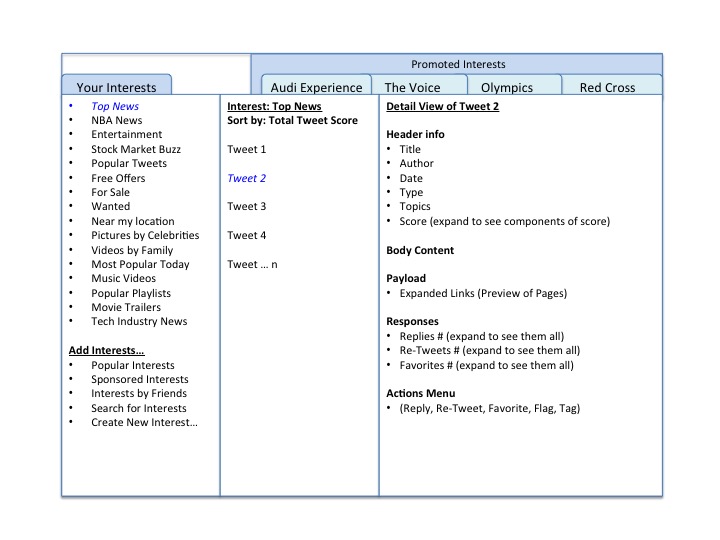
Now to make an app like this possible, Twitter needs to add richer metadata and semantics to Tweets. That’s the key to solving the signal-to-noise problem. Adding this additional semantic richness to the underlying data makes it possible to filter Tweets.
The best user-interface for doing this should be very “newsreader-like,” because in fact Twitter’s content is really very similar to news — it’s a stream of short updates and headlines that often point to payloads accessible via links.
Simple Semantic Tags
Currently all Tweets are just one type of message, a “status.” But what if users could simply add some tags to their Tweets, for type of message, just like they have been able to do in Flickr for example.
Flickr added the concept of “machine tags” – also called “triple tags” or “semantic tags” many years ago. Semantic tags are an elegant way to allow users to grow their own taxonomies of tag types in a totally bottom-up manner.
Simply allowing Twitter users to put their own semantic tags on Tweets would go a long way to making Twitter more useable, and would open up many huge possibilities.
For example, there could immediately be several basic tags that users could put on their Tweets such as:
- Twitter:Type=News
- Twitter:Type=Humor
- Twitter:Type=Advertisement
- Twitter:Type=Recipe
- Twitter:Type=Playlist
- Twitter:Type=Video
- Twitter:Type=RFP
- Twitter:Type=For Rent:Apartment
- Twitter:Type=Event
- Twitter:Type=Event:Live Event:Product Launch
Tags for types could also be added in the same way:
- Twitter:Topic=Sports
- Twitter:Topic=Sports:Football:NFL
- Twitter:Topic=Business
- Twitter:Topic=TV:Drama
- Twitter:Topic=Place:USA:New York:New York City
- Twitter:Topic=Entertainment
An even more powerful implementation would also support URIs in hashtags, which would enable more powerful formally defined and disambiguated semantics on Tweets, for example:
- Twitter:Type=http://www.heppnetz.de/ontologies/goodrelations/v1#BusinessEntity
To make this even better, Tweets should supply additional space for tags in the metadata part of each Tweet — perhaps a lot more space – so that adding more metadata to Tweets (which improves the signal-to-noise of the whole Twitter ecosystem) is not disincentivized by the 140 character limit.
Twitter could make all this non-geeky by simply putting a dropdown menu to add a type and one or more topics on a Tweet. More advanced users could add their own additional semantic tags to their hearts’ content.
If these tags existed on Tweets, it would then be possible to filter them in some very useful ways. For example, you could filter for just News, or just Sports News, or just Product Offers for Software, etc.
This would also enable the creation of much richer aggregations — including marketplaces and portals — that show particular types of Tweets for various topics.
These aggregations could be created by Twitter, but why not let anyone create them on Twitter’s site and in their apps, as well as via widgets in third-party apps? The more the better. They would all generate eyeballs and engagement for Twitter.
(Disclosure: My company Bottlenose has developed a way to automatically annotate Tweets with Type and Topic metadata, but we would love it if there was lots of community generated metadata on Tweets as well).
Filtering Tweets by Score
Not all Tweets are of equal value. The value of a Tweet has three components: (a) author value: the inherited value from the author, (b) audience value: the value to the audience, and (c) reader value: the value to a specific individual.
The author value of a Tweet is determined as a function of the influence score for the author. This can be determined by their follower count, or with a more sophisticated formula that measures the influence not only of the author but of the people who follow them, as well as the average level of response that the author’s Tweets generate.
The audience value of a Tweet is determined by the actual response from the author’s audience to the Tweet. How many responses were generated, in what timeframe, and what is the influence of the people who responded or shared it?
The reader value of a Tweet is determined by the relevance of a Tweet to the interests of a particular individual, as determined by their own Tweets in the past as well as any explicitly stated interests they share with Twitter (if it were possible to do do that).
Twitter should determine the cumulative value of a Tweet for each reader based on these three components of value. This would enable a smarter ranking of Tweets by a value score, and would also enable users to filter out Tweets below a certain value. The filter could be dynamic such that if a Tweet achieves a high enough value to beat a user-defined threshold it would appear.
Thus some users might only want to see Tweets that become high-value, whereas others who want to spot early trends before they get discovered by others could set a lower threshold. Ideally it should be possible to filter for a lower and upper bound to Tweet Value, in order to get any range of Tweets within the spectrum of value scores.
Note that users could also opt to turn on or off the personalization filter – they could see Tweets ranked by cumulative value of just Author Value and Audience Value, or they could add in the Author Value component to the filter to see a more personalized ranking.
Simple Semantic Streams
Once Tweets have metadata about their value, type and topic it becomes amazingly easy to filter them. This enables a much better Twitter consumption experience for consumers.
The above mentioned new metadata about value, type and topic would enable users to create streams that are defined by rules for value, type, topic, author, geography, and more. Most users won’t have time to define these however — so it should be possible for other users to create these rules and share them with groups or the public.
For example, a great stream rule for tracking “Tech Industry News” would be easy to define and share. This rule would pull Tweets of type News, with topic Technology, from particular authors. Note that this is much better than old-fashioned Twitter lists because in Twitter lists you had to see every Tweet by list members, where here there is much more focus (and therefore less noise).
Improving Two Big Ratios
Twitter already has a few built-in rewards for participation, such as potentially getting more followers, or getting likes. However, these are no longer as directly correlated with getting actual attention as before. The participation-to-reward ratio has fallen significantly and this means participation will naturally fall as well. This creates a vicious cycle into ever worsening participation.
The real currency that Twitter brokers is attention, yet by not controlling their signal-to-noise Twitter has actually lost attention to its core product. By losing attention, Twitter literally loses currency. It is attention, after all, that Twitter sells to its advertisers.
Fixing the participation-to-reward ratio depends on first fixing the signal-to-noise ratio. Certainly more gamification features could be added, but unless signal-to-noise is solved first, they won’t solve the root problem.
Twitter has to create more currency by attracting more attention and turning that into engagement. To do that they have to make it more worthwhile to spend valuable attention in Twitter’s offerings.
Unless the way that consumers interact with Twitter is made more efficient and rewarding, simply adding more bells and whistles or focusing on live events won’t help.
By enriching the underlying metadata in Twitter, and improving ease-of-use for tracking interests and filtering in Twitter, as well as by starting to apply automated filtering for users, the proper ratio of signal-to-noise can be restored.
Accessing Twitter Beyond Twitter
The final step is to make sure that consumption of Twitter doesn’t only happen through Twitter apps, as long as standards are adhered to.
Twitter should provide an unlimited public API again, where anyone and any app can get the last few thousand Tweets for any query and reuse them for free — as long as they also show Twitter ads, which would appear randomly in the stream at a ratio of 1 ad per 30 Tweets.
Those who don’t want to display the ads could buy out the ad space from Twitter and could put their own ads there or show no ads at all.
Twitter makes money either way, and they get a much broader surface area as a result.
One more thing — Tweets via the API would all be Twitter Cards and would contain web bugs that would report views back to Twitter and drop cookies anywhere they were displayed, enabling deep audience analytics even outside of Twitter.This would make Twitter’s retargeting and audience reach vastly larger than it is today.
Suddenly there would be literally millions of outlets for Twitter, all either showing Twitter’s ads or paying for the ad space, and all reporting their activity back to Twitter.
Note also that the full commercial firehose would of course still be available via Gnip, for those who need it (such as analytics companies like my own, Bottlenose), and the firehose would not have the same advertising requirements as the public API — in other words the firehose would have no paid ad slots in it because customers are buying the firehose data. However, the additional metadata proposed above would also dramatically increase the value of the firehose data to firehose data customers, making it far more filterable.
Conclusions
The simple semantic additions suggested above are simple to implement and would go a long way to improving Twitter engagement. They would also open up vast new markets and use-cases for Twitter data. I hope the time is finally ripe for Twitter to add some of these ideas to their roadmap. The incredible potential of Twitter has hardly been tapped. The best is yet to come.