Summary
A proposed experimental design to test whether consciousness of a future event improves the ability of humans and/or computers to predict that event. If we find that this is true, it implies the existence of consciousness, as well as retrocausality as a result of conscious observation. It may also be used as a method to test whether a computer is consciousness.
Hypotheses:
Hypothesis 1: People are better at predicting future events that they directly experience, compared to future events that they do not directly experience.
Notes: The question here is if people are better at predicting events in their own future mindstreams than events they don’t ever experience. Common sense implies the answer is yes. But we can test it to find out.
Hypothesis 2: People perform better at predictions of future events they directly experience than computers do at predicting future events they directly experience.
Notes: If true this establishes that something about humans outperforms computers at this task but what could that be? Perhaps it proves humans are conscious and computers are not? If yes, then this might be used as a kind of consciousness test in the future. Whereas the Turing Test tests for intelligence, this tests for consciousness.
Experimental design:
To test Hypothesis 1:
Ask humans and/or machines to predict the results of coin flips that will happen at a future date and time.
We call the party who makes the prediction “the predictor.”
At the allotted time in the future, randomly assign the task of doing the actual coin flip to a human or machine called “the detector.”
We randomly assign detections to either: (a) the predictor who was asked to predict it, or (b) a random detector (which might be a human or machine) that is not the original predictor, and is totally unknown to the predictor, and never reports the result to them.
- In case (a) the detector is the future self of the predictor. The detector does the future coin flip and therefore sees and knows the result of the coin flip.
- In case (b) the detector is not the future self of the predictor. The predictor does not do the future coin flip and never sees or knows the result of the coin flip.
We then compare the predictive accuracy of the predictions made for the coin flips in group (a) and group (b).
Are the predictions made for coin flips in group (a) more accurate than the coin flips in group (b)?
If the predictor and the detector are the same entity do we see different results than if they are not?
To test Hypothesis 2:
Test a set of human predictors vs a set of computer predictors in the above test. Compare the predictive performance of computers vs. human in the role of the predictor.
Note: Also be sure to test human versus machine coin flippers on both the side of the predictor and on the the side of the experimenter too – to rule out any influence of the consciousness of the experimenter impacting the results on the “non-predictor” coin flips (the fips that are not done by the predictor and not reported to the predictor).
To get more fancy we can test different time intervals between prediction and reflection of the prediction. We can also test other criteria that may contribute to the effect – such as group amplification, emotionality, and whether people perform better at predicting more engaging or memorable / novel events (for example instead of asking them to predict hundreds of coin flips that they don’t deeply care about, ask them to predict things like whether their own net worth or portfolio value – or some other measurable metric they care about – was up or down in the last 30 days.)
Possible Outcomes
Outcomes of the experiment can be classified into four logical permutations of the answer to the question, “Does test subject predict an answer in the future better than chance in the case where they are shown the answer in the future?”
The space of possible outcomes is summarized in the table below:
Human | Machine = Outcome
T | T = both are conscious
T | F = humans are conscious
F | T = computers are conscious
F | F = consciousness has no effect
Along with “conscious” in the table above we can add the term “retrocausal” – because it may appear that they co-occur and/or are aspects of the same phenomena – so in the cases where the result is T the subjects are not only conscious but there is evidence for a retrocausal effect: what happens in the future seems to affect the accuracy of a prediction in the past.
Like the Turing Test but for Consciousness
This experiment is akin to the Turing test, but where the Turing test detects intelligence, this experiment detects consciousness. And as a corollary, if the signs of consciousness are measured here it also implies that consciousness is some sort of a continuum where causality can flow from past to future and also from future to past.
What are the implications if we actually find that being conscious of an event has no measurable effect on the ability to predict it, and/or that both humans and machine predictors perform equally?
If we see higher predictive accuracy in the case of predictors (humans and/or computers) who eventually experience the target event vs predictors who do not, this indicates a form of retrocausality that is based on whether or not the party making the prediction is directly able to observe or know the result of the prediction.
Do the humans perform differently from the computers in a measurable way? This would support the hypothesis that humans possess something that machines do not, or vice versa. Or what if we find that both humans and computers are equally better at predicting answers they will eventually know? Does this mean they are both equally “conscious” or is it something deeper related to retrocausality?
If we find that humans are significantly better at performing this task versus computers this leads to the the question of why? Could it be that this indicates the presence of consciousness in humans and not in machines? If yes, can this be used to test if a machine is conscious?
It is also worth nothing that if these experiments fail to demonstrate the hypothesized effects of consciousness in humans and/or machines, that would be an interesting result as well. In fact, each of the possible outcomes lead to interesting philosophical conclusions.
Weak Signal Detection and Amplification
It is also worth noting that the hypothesized effect may be weak, and so detecting it may require a large number of tests before it begins to become visible in the data.
There are several ways to solve this, including testing a large number of subjects in parallel using a distributed workload system like Amazon Mechanical Turk to administer tests, or testing at higher speed per subject using automated testing systems.
Expanded Test Cases
We can also expand the experiment to test more cases:
Predictor | Detector = Outcome
H | H = X
H | M = Y
M | H = W
M | M = Z
The question is how does the experiment behave when the a human is a predictor and/or detector, versus when a machine is a predictor and/or detector?
If X, Y, W, and Z are probabilities of a correct prediction, then the hypothesis we are testing is: X > Y > W > Z
In other words the “human presence” increases a probability of a correct prediction proportion to the amount of “human influence” in the experiment. Another way of saying this is that the presence of human consciousness has a different effect than a machine on the accuracy of predictions, or if you like, we could says that “human consciousness” is better at predicting the future than “machine consciousness.”
Double-Slit Consciousness Detector Design
I have also given some thought to using quantum feedback loops to scale the effect.
For example, there may be a way to apply a double-slit experiment to run very large numbers of tests in short time intervals, where quantum entanglement and decoherence are utilized.
For example – consider a double slit experiment with a slight variation that we can utilize to run “consciousness tests” at high speed:
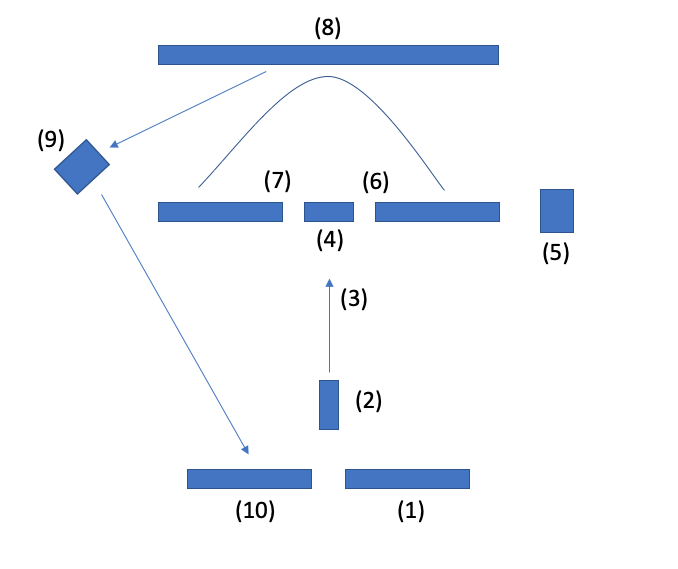
(1) A computer screen on which the user sees the visual representation of their predictions – perhaps using a joystick to generate a stream of 1 or 0 predictions. If they move the joystick 1 it generates more 1’s and this causes the screen to show a fringe pattern. If they move the joystick left it generates more 0’s and so the screen shows a Gaussian distribution pattern.
(2) A laser emits photons towards a double slit barrier.
(3) The photons are either a particle or a wave or both.
(4) The double slit barrier.
(5) A random number generator determines whether to measure to see if the photon passed through a slit (either slit 6 or 7), or NOT to measure if the photon went through a slit. If it measures, then the wave function collapses and if it does not measure the photons stay in superposition.
(8) A screen registers either a laser interference fringe pattern (in the case where no measurement was made), or a Gaussian distribution of the light (in the case where a slit was measured).
(9) A computer controlled shutter in front of a mirror reflects the image on the photon detector (8) to another screen (10), according to a randomized schedule. For example, half the time the shutter is open and the mirror reflects the result of the prediction on the target (8) back to screen (10), and half the time it does not.
To measure the results, compare the accuracy of the results that appear on screen (10) to the predictions made by the human on screen (1), and then compare these to the results where the human was not shown the result of the prediction.
If the image on screen (1) and screen (10) match more than 50% of the time, but the image on screen (1) and (8) match not more than 50% of the time, then we have proved the effect. In other words, when the user is shown whether the photon when through a slit or not, the images on (1) and (10) are more likely to match than if they are not shown.
Note: We might improve this design by making screen (1) and (10) the same screen – so that the user’s prediction and the result of the prediction are superimposed on the same screen and even interfere optically. This might improve the feedback loop.
Here is an instance of this improvement:
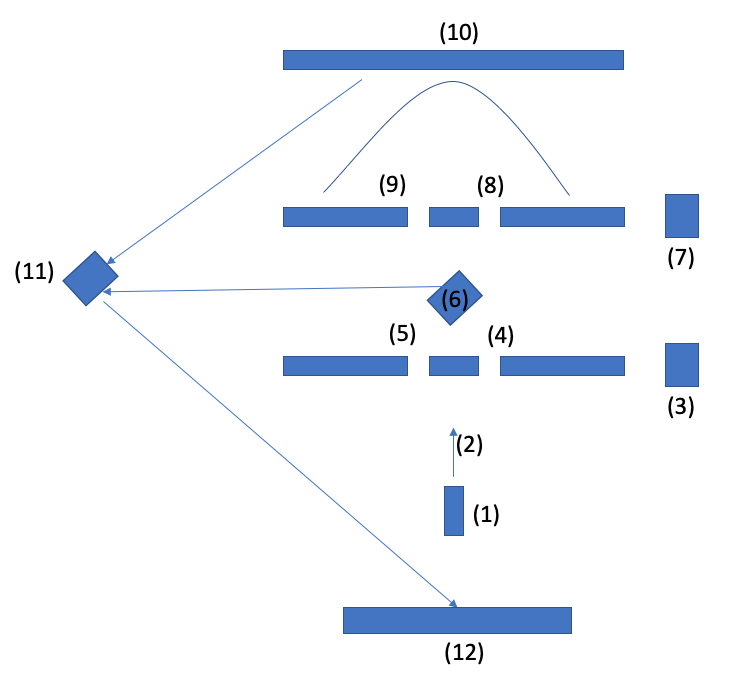
In the above version of the system, (1) is the laser, (2) is the light, (3) is a button that the predictor pushes to make a prediction of the light passing through one slit or both slits in the first double slit section (slits 4 and 5).
Next, (6) is a half silvered mirror that reflects the state of the light after passing through the first slits to the reflector (11) and thus to the target (12), to show the predictor the light pattern that represents their prediction.
Meanwhile, half the light passes through (6) and goes to the second double slit detector comprised of slits 8 and 9. The light that passes through these slits may have been decohered by the prior slits, but again this decohered pattern enters into superposition when it passes through slits 8 and 9, unless again this second set of slits are measured to determine if a photon passed through a particular slit or not.
(7) A random number generator determines whether to measure to see if the photon passed through a slit (either slit 8 or 9), or NOT to measure if the photon went through a slit. If it measures, then the wave function collapses and if it does not measure the photons stay in superposition.
(10) A screen registers either a laser interference fringe pattern (in the case where no measurement was made), or a Gaussian distribution of the light (in the case where a slit was measured).
(11) A computer controlled shutter in front of a mirror reflects the image on the screen (10) to another screen (12) according to a randomized schedule (and note if needed we can insert another mirror to un-reverse the image due to the mirror reversing it). The ratio of the shutter determines the ratio of tests between human and machine detectors. For example, in the default case, we would set it so that half the time the shutter is open and the mirror reflects the result of the prediction on the target (10) back to screen (12), and half the time it does not. In the cases where the human predictor is shown the result, this is equivalent to a case where the human is the detector. In the case where the human is not shown the result, this is equivalent to the case where the machine is the detector (and it should be noted that all results are tabulated by an independent third party that is neither the human predictor nor the machine detector).
The result is that screen 12 will show both the predicted pattern and the actual pattern in the same place, with the same light source.
Because the predicted pattern occurs before the actual pattern, if they are not the same pattern then there will be a flicker effect as the image switches from one to the next. Therefore the flicker rate will be an indicator of the similarity between the predicted and actual pattern on the photon detector in a stream of many rapid tests. We can measure the flicker rate as a means to quantify the predictive accuracy of the human at high speed.
A Note About Sending Messages Backwards in Time
If the above hypotheses hold, then an astute reader might then ask could a system like this be used to send messages backwards in time? I spent a good deal of time pondering this question. The simple answer is “maybe.” We can test it using this setup in fact.
How does this work? When a human makes a series of coin flips the result should be a random distribution. But if we know the coin flips MUST correlate to the future results at the detector, then if we manipulate the future results in a non-random way in the future, it forces the coin-flips in the past to have a non-random distribution.
So to send a message from the future to the past we trick the person doing the detection in the future by artificially varying what they measure – by varying the non-randomness we inject at the future point of detection – for example by artificially inserting more “heads” results into the data for example” than a random distribution could include, thus causing the person doing the detection to see more heads in their results.
Then by doing this in a way that encodes a message into the non-random future detection stream, a past stream of coin flips can be manipulated such that a message can be transmitted back in time.
The message is detected by the person doing coin flips in the past (who knows that the future experiment is designed to send them messages in this manner and knows the decoding method) when they analyze the stream of coin flips they made, and detect and measure the non-randomness of the series of coin flips they made.
The quality of non-randomness encodes the message. Let 0 = tails and 1 = heads. Then we define that in a stream of 1000 coin flips a more than a random distribution of 0’s = 0, else a more than random distribution of 1’s = 1. Then do 1000 coin flips and see if you get more 0’s or 1’s than randomness would allow and that is the first bit in the message. Then repeat for n bits to complete the message.
We can further refine this by having the human predictor in the past make two streams of coin flips. One stream contains the message and the other stream is a control stream with no message. We weave these two streams together by simply making different flips belong to different streams randomly. So for example we do 2000 coin flips and we randomly assign each flip to either the message stream or the control stream. In the future we manipulate the results accordingly by weighting the dice of each flip (a message) to place it in the message stream or not weighing it (no message) to place it in the control stream.
When we separate the flips in the stream in the past into message flips vs control flips, we should see the message in the messages stream and no messages in the control stream.
Experimental Philosophy
This experiment provides a way to physically test and measure certain philosophical questions about the hypothetical effects of human vs. machine consciousness and/or the effect of conscious observation, or the lack thereof, on predictions about the future.
If it succeeds in demonstrating the effect of conscious observation on prediction, it is a world-changing result. If humans perform better than machines this implies that there is something about human observation that machines cannot replicate, and/or this could be a way to quantify subtle gradations in the levels of human and machine consciousness, if we look at it this way.
But even if it fails to detect the hypothesized effects, that also tells us something important. If we find that humans do not perform any differently than machines on this task then it is evidence that consciousness does not exist, or at least it is not retrocausal, and/or that humans and machines are either equally conscious or equally non-conscious.
The proposed experiment might be a ripe medium for what I call “experimental philosophy.” It could be to philosophy what experimental physics is to theoretical physics, providing a mechanism to experimentally test philosophical views about mind vs. machine.