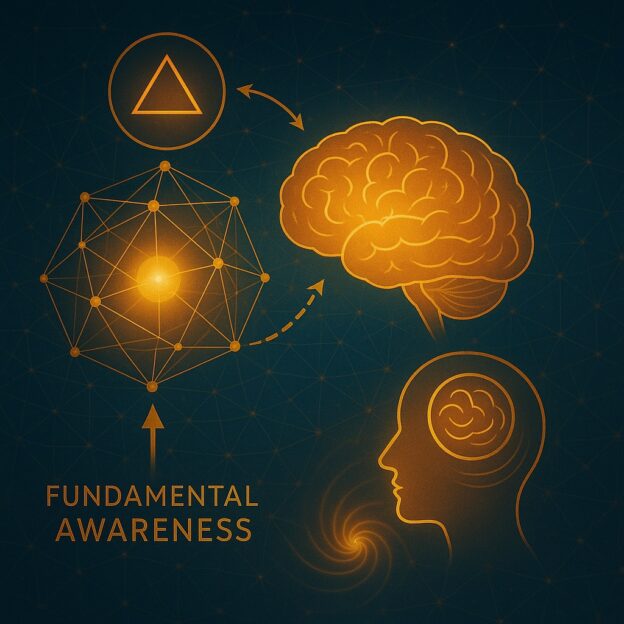
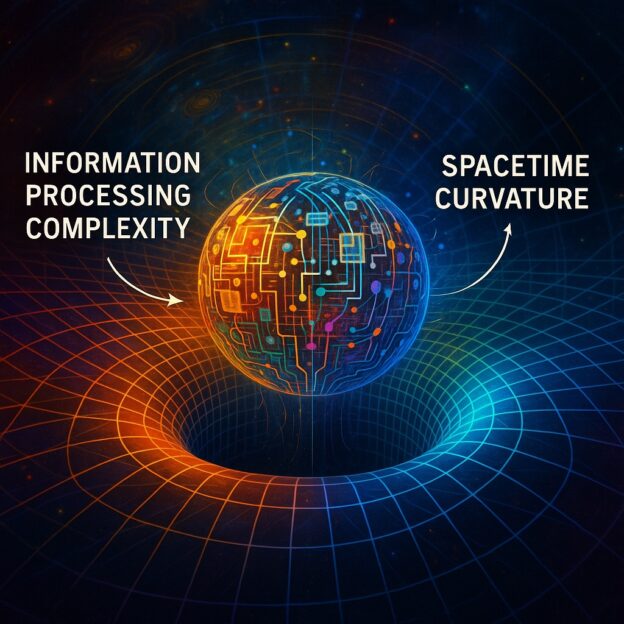
What This Work Is About
This article explains our paper on a new mathematical framework for self-referential systems, for a non-technical audience. The paper develops a comprehensive mathematical framework for understanding systems that can represent, model, or “know” themselves. While self-reference has long been seen as a source of logical paradoxes, this work argues it may be the fundamental organizing principle of reality itself—and provides specific mathematical bounds and requirements for achieving different levels of self-awareness.… Read More “A New Mathematics of Self-Reference: A Comprehensive Non-Mathematical Summary”