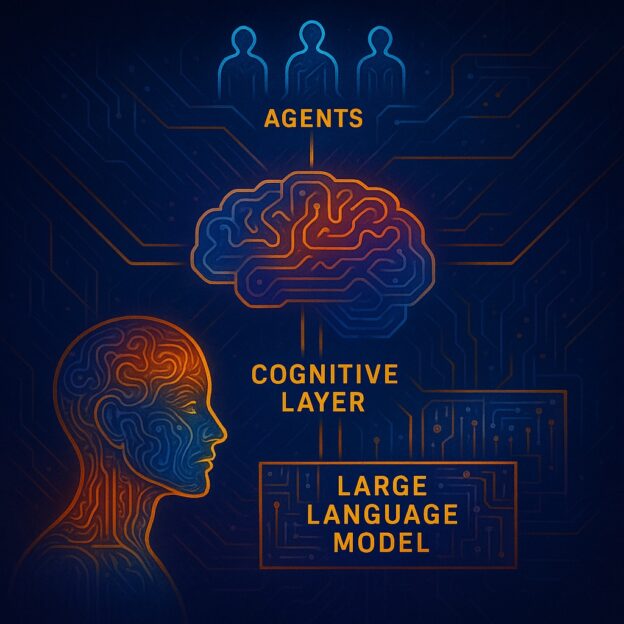
My arXiv article on the future of AI is live.
… Read More “Cognition is All You Need – The Next Layer of AI Above Large Language Models”Recent studies of the applications of conversational AI tools, such as chatbots powered by large language models, to complex real-world knowledge work have shown limitations related to reasoning and multi-step problem solving.