Check out this amazing new artificial life simulation I have developed.
Click here to run it in your browser
(It’s graphics intensive so it’s best if you have a high performance modern computer like a multicore mac or pc.)
Turn the sound on to hear the alien soundscape (use the checkbox on the HUD)
Summary:
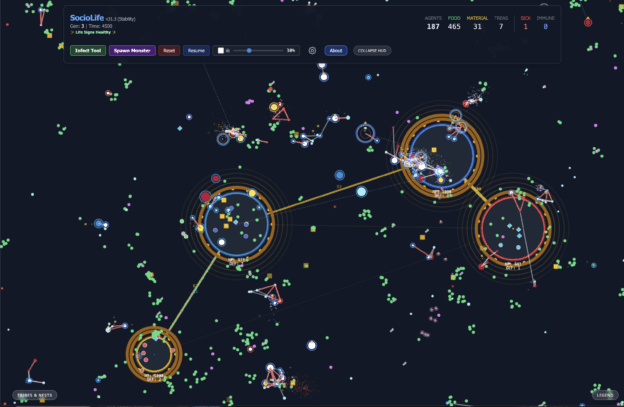
SocioLife evolves intelligent agents with DNA that evolve and interact, forming complex societies that then engage in economic, diplomatic, and military relations.… Read More “SocioLife – A Socio-Economic Artificial Life Sim That Runs in your Browser”